Table of Contents
What is Indexed Not Submitted in Sitemap?
Indexed, not submitted in sitemap is a field in the Google Search Console Coverage report. It tells webmasters when Google crawlers have found URLs that are not part of the website’s .xml sitemap but they are indexable anyway.
Most of the information found on the internet about this subject will tell you that having URLs that are indexed and not submitted in your sitemap is not an issue that deserves attention. However, at NextLeft, we’re here to tell you that is just plain WRONG and here’s why.
What is Over-Indexation?
In a perfect scenario, a search engine would only index the number of URLs that are present in your .xml sitemap. However, over-indexation can occur when search engines begin to crawl additional pages and start indexing too many pages on your website.
You may be thinking – I want search engines to index every page on my site, right? Think again! There are plenty of situations where pages that are live on your website don’t belong in the index. A few examples include pages that:
- Exist behind a log in
- Return an error code
- Have no organic search intent
- Have duplicate intent or targeting
The Effects of Over-Indexation
Think of this analogy. You are running in a race. Do you want to carry a full backpack with unnecessary weight while you run? No! You want to be as light and streamlined as possible. The same is true for websites!
Being over-indexed has a number of negative effects, including:
- Decreased Rankings: Chances are the majority of the URLs that are getting indexed but are not in the sitemap should not be indexable. They are generally low-quality or duplicate pages that have no organic value.
- Reduced Crawl budget: Crawl budget is the number of URLs that robots or spiders want to crawl. The more low-quality or broken pages that are in the index, the less likely and frequently Google will return and crawl important pages.
- Poor Link Juice Distribution: Link juice is given and taken via links, both internally and externally. Do you want that finite amount of juice to be spread out across a number of low-quality or duplicate pages that have no organic value? Of course not! That equity should be shared only to pages that have a chance to rank for keywords. Think back to the analogy above; your website doesn’t need dead weight and link juice should be concentrated on the highest value organic pages.
- Poor User Experience: If a user lands on a 404 page, gets redirected to another page from search results or enters your site through a low-quality page, your website is providing the user with a poor experience and they will likely bounce.
How to Check Over-Indexation?
1. Ensure the Sitemap is Correct
In order to determine if a website is over-indexed or not, you need to know that the sitemap is correct. Since your sitemap is all of the URLs that a search engine should crawl and index, the URLs in the sitemap will act as the baseline number for comparison. Any number over that merits some level of investigation.
Most sitemaps are automatically generated and updated by CMS, plug in or app, but that doesn’t mean they are error free. Start by crawling the sitemap with a tool like Screaming Frog to look for any errors. Then, double-check that it is both submitted and can be read by a service like Google Search Console or Bing Webmaster Tools.
Q: Does it appear that important folders or pages are missing from the sitemap?
A: If so, identify which pages are missing and ensure that they are included in the sitemap.
Q: Are canonical URLs found in the sitemap?
A: The sitemap should only contain representative URLs and not URLs that have a different canonical.
Q: Do any pages return error codes?
A: Any pages with 3xx, 4xx, or 5xx error codes will need to be fixed or removed.
Q: Are no-indexed pages still appearing in the sitemap?
A: Oftentimes this means the sitemap needs a refresh or the cache needs to be cleared. If that doesn’t work, further investigation will be required.
Q: Are pages in the sitemap being blocked by robots.txt?
A: Sending mixed signals to search engines can result in both under and over-indexation issues.
If any of these errors above are found, they will need to be addressed before performing our audit.
2. Use the Search Console Coverage Report
* For the purposes of this post, we will be using Google and Search Console as our main search engine auditing tool but this process will fix issues across all search engines.
Once it is established that the sitemap is accurate, turn your attention to the Search Console Coverage Report. There are a number of fields in this report (Errors, Valid with Warnings, Excluded) that will not be covered in this post. For our purposes, pay special attention to Valid field, and more specifically, indexed, not submitted in sitemap.
It is common for there to be some URLs in this field and this number will almost never be zero. However, if the number of URLs here is 20% of the amount of URLs in your sitemap or more, then there is a problem. Either these URLs are valid and should be included in your sitemap or they are indexation errors, there is no in-between!
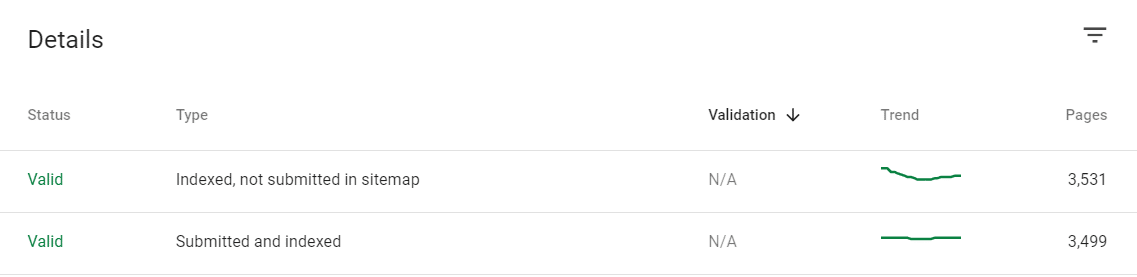
* Here’s an example of a website that is way over-indexed and experiencing decreased performance.
Common Over-Indexation Errors & Fixes
Unfortunately, Google only provides up to 1000 URLs via the indexed, not submitted in sitemap report. Depending on the issues facing a website, there may be more URLs in this section than can be exported as in the example above. However, even if every URL can’t be seen, it will still allow you to identify patterns, draw conclusions on where these URLs are coming from, and recommend fixes. Some common indexation issues for not sitemap URLs include, but are not limited to:
- URLs with parameters
- Filter URLs
- Duplicate content
- Low-quality pages
- URLs with error codes
- URLs indexed though blocked by robots.txt
1. URLs with Parameters
A URL parameter is a way to pass information about a click through its URL. It can be identified by a ? in the URL string – for example (?product=5427&utm_source=google). Parameter URLs can take on a variety of forms, including UTM, internal site search, or filter parameters. While URL parameters serve a valuable purpose, they can become problematic if indexed since it is the same page but just with a query parameter string at the end.
The Solution
When URLs with parameters get indexed, this generally means there is an issue with canonicalization.
- Canonical URLs are missing or incorrect.
- Canonicals are not being respected and the page is getting indexed anyway.
After fixing any canonical issues, check the Google Search Console parameters tool and add in any parameters to help Google understand how to crawl and handle these pages.
2. Filter URLs
Filter URLs are used to sort items (like products) on a page.
Think of an eCommerce website. Generally, there are options to sort by criteria like price, most popular, or top-rated. Depending on the page, there may be multiple combinations of filters that can be applied to a page. If all of these variations happen to get indexed, there can be a massive amount of duplicate pages floating around search results.
The Solution
Most filter pages should be non-indexable either via canonicalization or no-index tag. In fact, CMS’s (like Magento or Shopify) automatically use parameters and canonical filter pages back to the original category page to keep them out of the index. It’s well understood that there is usually no search volume for these filter pages and they are only for users on site.
* This does not necessarily mean that all filter pages should be no-indexed. For some websites, we’ve found that it may make sense for certain filter pages to be indexable. For example, there may be search volume for pages that are filtered by color, size, or brand. A little keyword research can go a long way in helping you make this judgement call. If there is opportunity, make sure these filter pages are added to your sitemap!
3. Duplicate Content
Duplicate content found outside of sitemaps can come from a variety of places. A few common examples include:
- A recent migration where pages weren’t properly redirected.
- Parameter, internal search or filter URLs as mentioned above.
- Similar pages that were programmatically generated.
These are just a few common scenarios, but duplicate content can take on many forms.
The Solution
Depending on the situation, the goal here is to first identify the source any duplicates. Depending on the type of page, ensure that these pages are removed and redirected or made non-indexable.
4. Low-Quality Pages
It’s no secret that Google values high-quality content and devalues low-quality content, especially if it is present on a large scale. Low-quality content doesn’t necessarily mean pages that are poorly written. In this case, it means thin pages that were programmatically generated on a large scale like image attachments, soft 404s, or indexable pdfs that serve no organic purpose for users. If a page looks like something no one would ever search for organically, then it probably shouldn’t be indexed.
The Solution
Similar to duplicate content, the goal is to identify the source of these pages and make a fix. Fixes can include removing the pages and setting up redirects, using no-index tags, or implementing x-robots tags for pdfs.
5. URLs with Error Codes
Although search engines like to drop URLs with errors codes out of the index, there can be situations where these types of pages hang around. They can come from a variety of places, but the most common errors include:
- 404s: This means that an indexed page was deleted or the URL changed and no redirect was set up from the old version to the new version. Although 404s will generally drop out of the index over time, you will want to ensure that any important pages get redirected to preserve traffic and link equity.
- 301s: If a URL has been properly redirected, it will generally fall out of the index over time as Google crawls and finds the new page. If these URLs linger for some time or you are seeing different types of redirects (ie 302s), you may have to investigate the source further.
* Sometimes a URL that is well internally linked throughout your website can remain in the index, even if it returns an error code. Yet another good reason to do broken internal link clean up!
6. Indexed Though Blocked by Robots.txt
This is an error that occurs when a URL has been indexed by Google, but it is also being blocked by the robots.txt file. This pertains to indexation because it can affect pages with error codes by keeping them in the index even though they should have been crawled and removed (see above). Since robots.txt is blocking the page from being crawled, a search engine cannot see the change in response code. Therefore, based on the last time it was crawled, it looks like a perfectly normal page that should be displayed in SERPs.
The Solution
- Ensure that the pages being blocked are handled correctly whether that means they are redirected, no-indexed, canonicalized, or have a proper 200 response code.
- Remove the blocking directives from the robots.txt file. Use the Google Search Console robots.txt tester to identify the blocking directives!
- Wait for the pages to be crawled or resubmit the site for crawling and let the search engines work their magic. This may take some time depending on the number of pages in question.
Case Study
This is a lot to take in. So why is doing this audit and making the necessary fixes so important?
Here are a few screenshots from a client below. They are on WordPress and mistakenly had the below setting in Yoast set to “No” for many years.
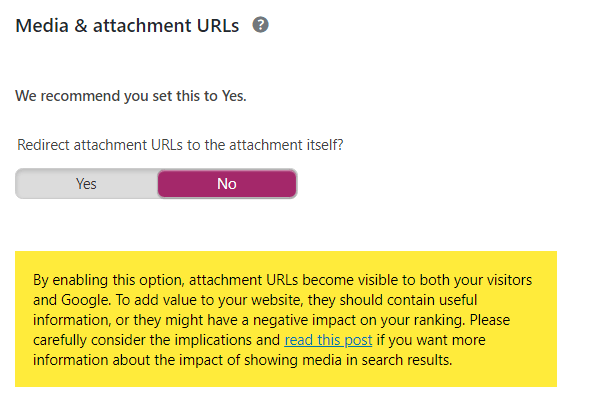
This meant that any sort of image that was uploaded to the website created a separate attachment URL that returned a 200 response code. Multiply this out over 10+ years of uploading images and this had the effect of massively over-indexing this website. For a site with only about 400 pages in their sitemap, they had over 4,000 URLs in their index! Almost all of these were just an image sitting on its own URL with no other content.
The Fix
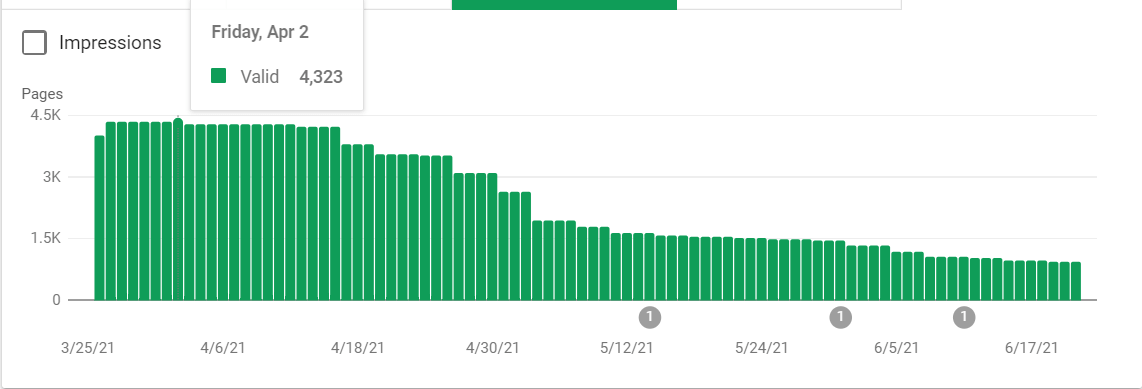
The ONLY change NextLeft made was changing the above WordPress setting to “Yes” which 301 redirected all of these image URLs back to the image itself. As Google saw that these URLs were being redirected, they started to drop out of the index as expected. In about two months, the site went from about 3800 URLs indexed, not submitted in sitemap to about 500.
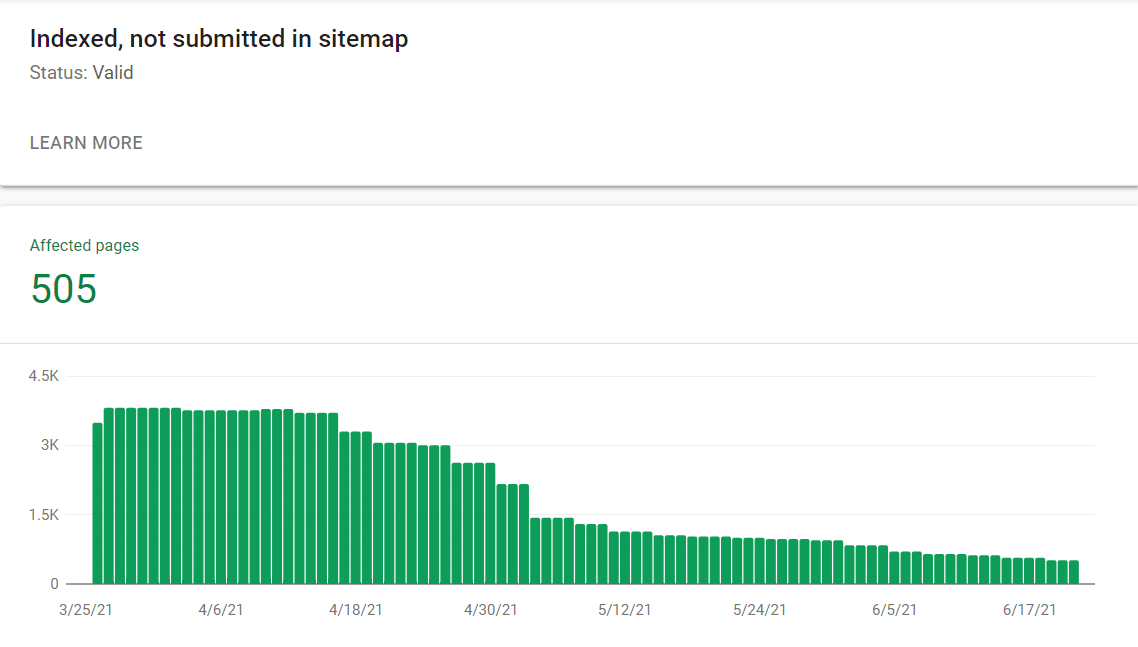
As the site’s level of indexation began to improve, we saw almost immediate results. Look at the screenshots below. During this same time period as massive amounts of low-quality URLs were falling out the index, our average rank improved over 27%, increasing our share of voice and estimated traffic value.
![]()

Again, the ONLY change we made during this time period was changing one setting to start cleaning up the image attachment URLs. While we’ve seen similar results from doing indexation audits for other clients, these results happen as other updates are being made at the same time. This fix occurred in a controlled environment and the correlation is undeniable. As low-quality URLs were removed from the index, rankings shot up.
Contact Us for an Indexation Audit Today!
So what’s the takeaway here? Being over-indexed matters and fixing this issue can have dramatically positive results. Don’t believe us? Let NextLeft do an indexation audit for your website. Contact us today to get started!